En el post anterior describí el pipeline de clasificación: Music Flamingo en GPU para el audio, gemma para procesar letras, OpenAI para embeddings, todo orquestado por un worker que va consumiendo jobs de PostgreSQL.
Mientras el análisis de audio sigue corriendo (limitado por la PSU del server), las letras ya están completas: 1,934 tracks scrapeados, traducidos al inglés, analizados con keywords/topics/themes/sentiment, y vectorizados como embeddings de 1536 dimensiones.
Con esos vectores en mano, este post hace algo concreto: agrupar la biblioteca por similaridad semántica de letras usando UMAP + HDBSCAN, primero en clusters finos (level 1) y después agregando a macro-grupos temáticos (level 0).
Los datos disponibles
De los 14,502 tracks registrados por el scanner:
| Etapa | Tracks |
|---|---|
| Total escaneados | 14,502 |
Con letra encontrada (lyrics_fetch) |
1,935 |
| Letras traducidas al inglés | 1,935 |
| Letras procesadas (keywords/topics/themes) | 1,935 |
Letras con lyrics_embedding |
1,934 |
El gap entre 14,502 y 1,935 viene de dos cosas: la mayoría de la biblioteca aún espera
que termine music_analysis (que dispara la cascada de letras), y los tracks instrumentales
o con metadatos sucios no encuentran letra. La tasa de fallo de lyrics_fetch rondó el
18% — los buscadores tiran 429/403 cuando uno los hostiga durante horas.
Distribución por sentiment:
| Sentiment | Tracks |
|---|---|
| negative | 851 |
| ambiguous | 758 |
| positive | 282 |
| neutral | 44 |
Distribución por idioma de letra original:
| Lang | Tracks |
|---|---|
| en | 1,792 |
| ja | 101 |
| de | 19 |
| is | 5 |
| fr | 4 |
Predominio aplastante del inglés, con un núcleo notable de japonés (Ado, Babymetal, Samurai Champloo, Evangelion OST) y algo de alemán (Brutalismus 3000, Wolfenstein OST).
Por qué UMAP + HDBSCAN
Cada track tiene dos vectores semánticos: lyrics_embedding (la letra completa traducida)
y topics_embedding (los keywords/topics/themes/sentiment como texto compacto). Ambos
son de 1536 dimensiones, generados por text-embedding-3-small de OpenAI.
Clusterizar directo en 1536d con HDBSCAN no funciona bien — la "curse of dimensionality" infla las distancias y todo termina pareciéndose. La receta estándar para embeddings es:
- UMAP para reducir a ~15 dimensiones preservando la estructura local
- HDBSCAN para encontrar clusters de densidad variable, marcando como ruido lo que no encaja
A diferencia de k-means, HDBSCAN no requiere especificar el número de clusters y maneja clusters de tamaños y densidades distintas. Además te dice explícitamente qué puntos no pertenecen a ningún cluster (los marca como -1) en vez de forzarlos en el más cercano.
La receta exacta
import numpy as np, json, hdbscan, umap
# 1) Combinar lyrics_embedding (peso 0.5) + topics_embedding (peso 1.5)
# Los topics son más semánticos — mejor señal de tema que la letra cruda
mix = np.concatenate([0.5*lyrics_v, 1.5*topics_v], axis=1)
mix = mix / np.linalg.norm(mix, axis=1, keepdims=True)
# 2) UMAP a 15 dims con métrica coseno
reducer = umap.UMAP(n_components=15, n_neighbors=10, min_dist=0.0,
metric="cosine", random_state=42)
emb = reducer.fit_transform(mix)
# 3) HDBSCAN con cluster_selection_method='leaf' para clusters finos
clusterer = hdbscan.HDBSCAN(min_cluster_size=12, min_samples=3,
metric="euclidean",
cluster_selection_method="leaf")
labels = clusterer.fit_predict(emb)
El parámetro clave es cluster_selection_method="leaf": con "eom" (el default) sale
una jerarquía gruesa con pocos clusters grandes; con "leaf" sale más granular —
exactamente lo que queremos en este nivel.
Visualizando la biblioteca
UMAP 2D coloreado por macro-grupo:
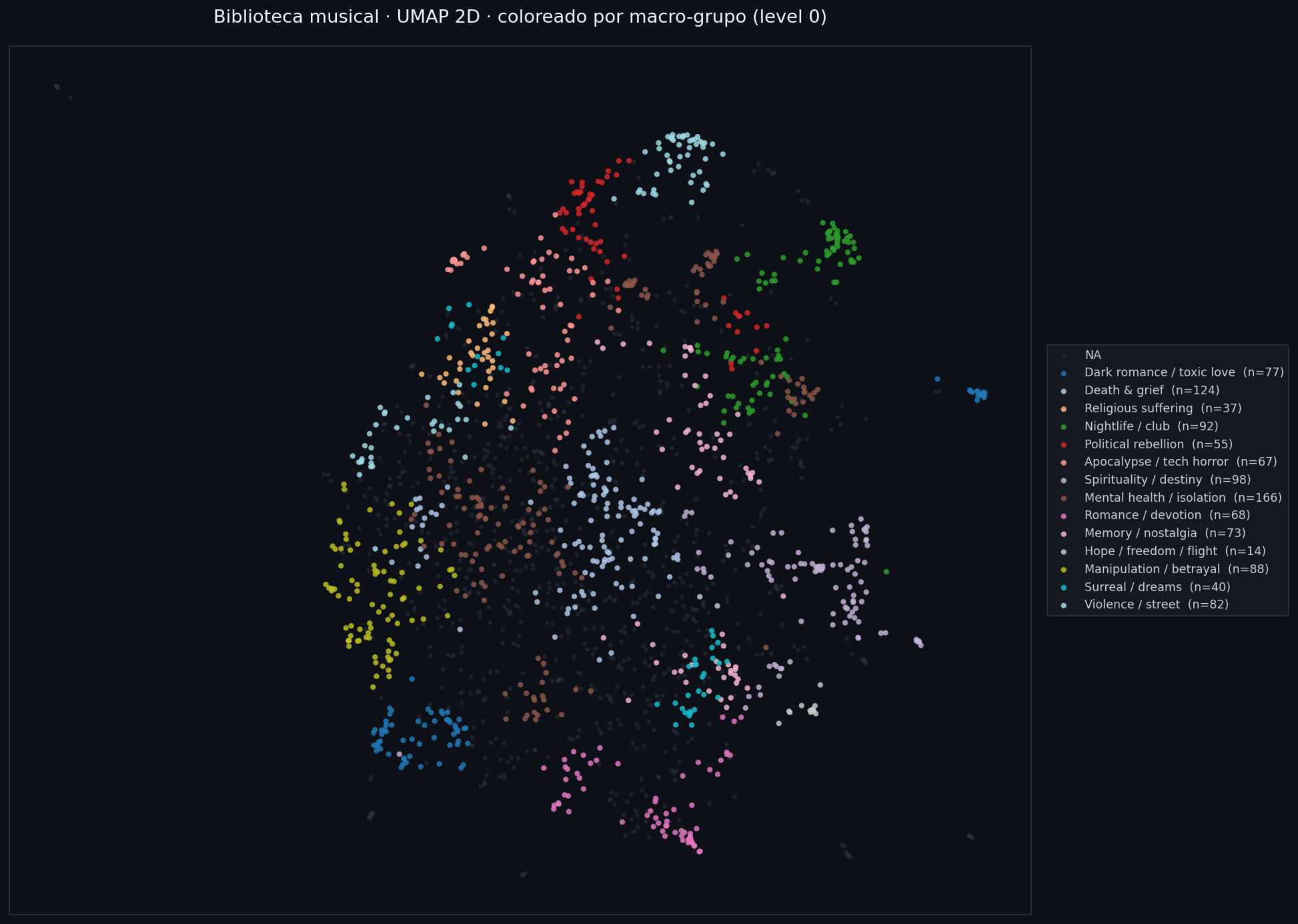
Cada punto es un track. Los grupos cohesivos en la periferia son los clusters densos (géneros temáticos bien definidos); el blob central gris son los 853 tracks que cayeron en NA — tracks demasiado diversos, instrumentales con metadatos ruidosos, o que combinan temas de varios clusters sin pertenecer claramente a ninguno.
Level 1: 45 clusters finos
El primer pase de HDBSCAN dio 45 clusters identificados + 853 NA (44.1% de noise rate, alto pero esperable cuando faltan los embeddings de audio que añadirían señal acústica).
Los 12 clusters más grandes:
| # | Label (auto) | Tracks | Sample |
|---|---|---|---|
| 4 | Music / Nightlife | 53 | Fatboy Slim — The Weekend Starts Here |
| 40 | Isolation / Identity | 52 | Flyleaf — I'm So Sick |
| 8 | Violence / Wealth | 48 | Run The Jewels — Legend Has It |
| 32 | Death / Memory | 47 | AFI — Now the World |
| 10 | Escapism / Urban Life | 45 | Roxy Music — Grey Lagoons |
| 9 | Political Corruption / Class Warfare | 43 | Sex Pistols — God Save The Queen |
| 14 | Identity / Materialism | 39 | Rush — Subdivisions |
| 38 | Religion / Suffering | 37 | Sisters of Mercy — This Corrosion |
| 36 | Betrayal / Conflict | 33 | Sex Pistols — Liar |
| 16 | Divinity / Destiny | 32 | Evangelion — Cruel Dilemme |
| 23 | Heartbreak / Obsession | 30 | Stevie Ray Vaughan — Cold Shot |
| 22 | Heartbreak / Longing | 29 | She Wants Revenge — Broken Promises For Broken Hearts |
Los labels son generados automáticamente concatenando los dos topics más frecuentes del cluster. Salen genéricos cuando varios clusters comparten topic principal (hay 4 clusters distintos con "Identity / X"), pero como base sirven y son auditables.
Cómo se ve el detalle de un cluster
Cluster #25 "Medical Horror / Biological Warfare" (n=15):
Topics dominantes: medical horror, biological warfare, psychological trauma,
industrial decay, political corruption, societal collapse
Themes: physical and mental fragmentation, technological dystopia,
dehumanization of the individual, existential dread
Keywords frecuentes: Incision, Assimilate, Trauma Hounds, Hospital Waste,
VX Gas Attack, Convulsion
Sentiment: 100% negative
Idioma: 100% inglés
Samples:
- Bring me the horizon — Parasite Eve
- Sex Pistols — Bodies
- Siouxsie & The Banshees — Switch
- Skinny Puppy — Tomorrow
Es un cluster pequeño pero conceptualmente impecable: el modelo entendió que Parasite Eve (post-pandemic body horror), Bodies (sobre aborto) y los grunidos industriales de Skinny Puppy comparten el mismo registro semántico de "horror corporal / contaminación industrial".
Level 0: 14 macro-grupos
45 clusters finos son demasiados para navegar como humano. Definí 14 macro-grupos temáticos con keywords ponderadas, y para cada cluster de level 1 calculo qué macro matchea mejor.
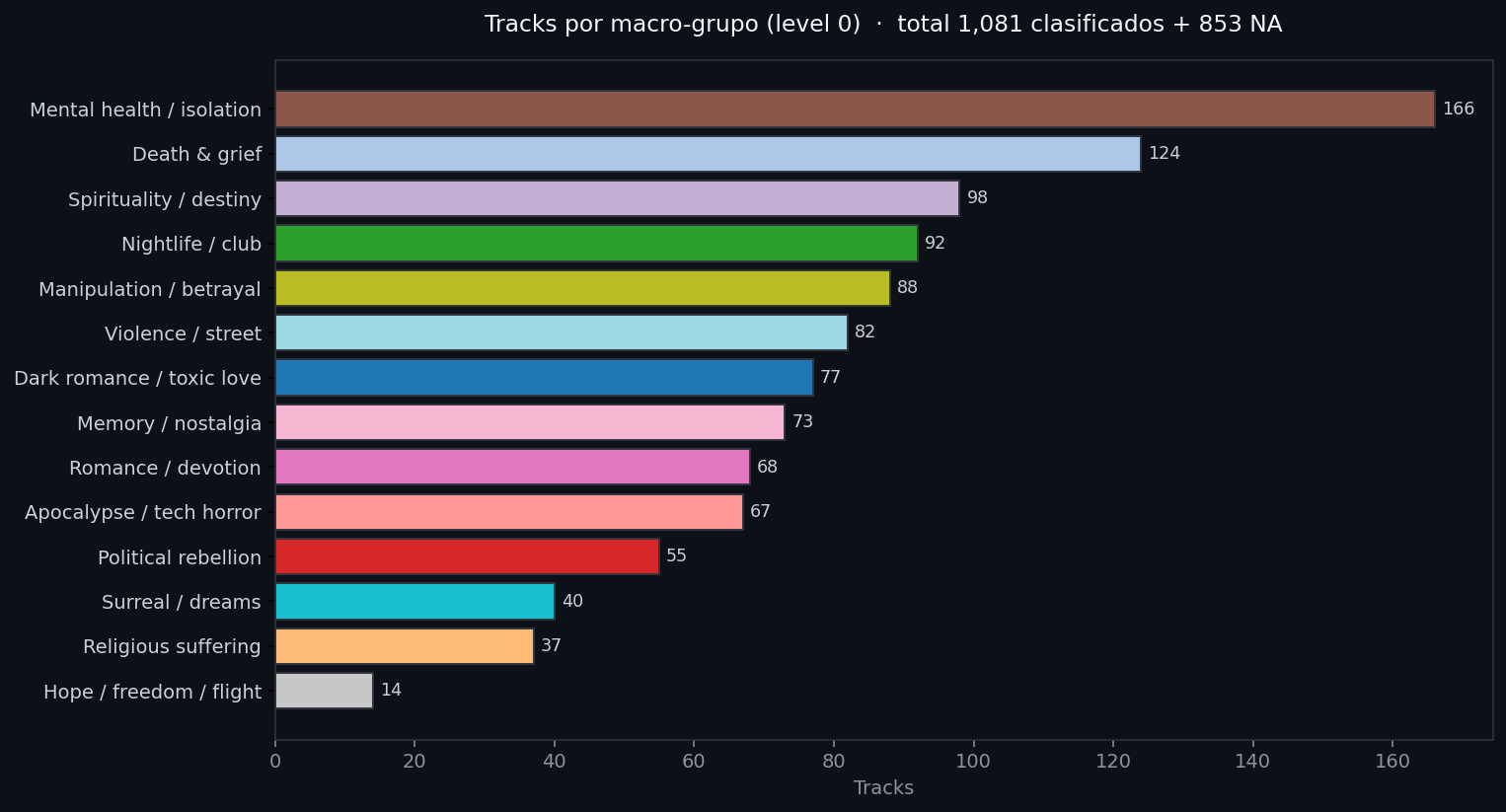
Resultado:
| # | Macro | Tracks | % |
|---|---|---|---|
| 7 | Mental health / isolation | 166 | 15.4% |
| 1 | Death & grief | 124 | 11.5% |
| 6 | Spirituality / destiny | 98 | 9.1% |
| 3 | Nightlife / club | 92 | 8.5% |
| 11 | Manipulation / betrayal | 88 | 8.1% |
| 13 | Violence / street | 82 | 7.6% |
| 0 | Dark romance / toxic love | 77 | 7.1% |
| 9 | Memory / nostalgia | 73 | 6.7% |
| 8 | Romance / devotion | 68 | 6.3% |
| 5 | Apocalypse / tech horror | 67 | 6.2% |
| 4 | Political rebellion | 55 | 5.1% |
| 12 | Surreal / dreams | 40 | 3.7% |
| 2 | Religious suffering | 37 | 3.4% |
| 10 | Hope / freedom / flight | 14 | 1.3% |
El sesgo de la biblioteca queda evidente: la mitad de los tracks están en macros oscuros (mental health, death, manipulation, dark romance). Tiene sentido dado los artistas dominantes — AFI, Deftones, BMTH, Sopor Aeternus, Sisters of Mercy.
Ejemplos por macro-grupo
Mental health / isolation (166)
- AFI — Three and a Half (3 1/2)
- Yo La Tengo — Saturday
- Yeah Yeah Yeahs — Man
- Bring me the horizon — sTraNgeRs
Death & grief (124)
- Soundgarden — Like Suicide
- Queen — White Queen (As It Began)
- AFI — A Story At Three
- Silversun Pickups — Sort Of
Spirituality / destiny (98)
- Rush — The Trees
- Babymetal — Shanti Shanti Shanti
- Rush — Marathon
- Hades OST — Hymn to Zagreus
Nightlife / club (92)
- DJ Shadow — Back to Front (Circular Logic)
- Fatboy Slim — Song For Shelter
- Brutalismus 3000 — Liebe in Zeiten der Kola
Manipulation / betrayal (88)
- Freezepop — Manipulate (Mastermind Mix)
- Bring me the horizon — Throne
- Zeromancer — Houses of Cards
- Stone Temple Pilots — Sex Type Thing
Violence / street (82)
- Run The Jewels — Oh Mama
- Slipknot — Diluted
- DJ Shadow — Keep Em Close
- Deftones — Knife Prty (Purity Ring Remix)
Dark romance / toxic love (77)
- She Wants Revenge — All Those Moments
- Deftones — Teenager (Robert Smith Remix)
- Sisters of Mercy — A Rock and a Hard Place
- Queen — Man on the Prowl
Memory / nostalgia (73)
- Yo La Tengo — Night Falls On Hoboken
- Steely Dan — Third World Man
- Sonic Youth — Sweet Shine
Romance / devotion (68)
- She Wants Revenge — Kiss Me
- Pulp — Something Changed
- Boa — On the Wall
Apocalypse / tech horror (67)
- Brutalismus 3000 — GR3Y
- Bring me the horizon — Parasite Eve
- Skinny Puppy — Christianity
- Evangelion — Carnage
Political rebellion (55)
- Fela Kuti — Unknown Soldier (Part 1 & 2)
- Sick Of It All — Chip Away
- Wolfenstein — The New Colossus (Mick Gordon)
Surreal / dreams (40)
- Sigur Rós — Glósóli
- Siouxsie & The Banshees — Drifter
- Shocking Blue — The Butterfly And I
Religious suffering (37)
- Soundgarden — Jesus Christ Pose
- Stone Temple Pilots — Sin
- AFI — So Beneath You
Hope / freedom / flight (14)
- Evangelion — 翼をください (Tsubasa wo Kudasai)
- Sigur Rós (via cluster #3 vecino)
- Silversun Pickups — Songbirds
Que Sigur Rós y la versión de Tsubasa wo Kudasai (himno escolar japonés clásico) caigan cerca tiene mucho sentido — ambos comparten el registro de elevación etérea sin importar el idioma.
Schema persistido en PostgreSQL
Los resultados quedan en dos tablas nuevas:
CREATE TABLE track_clusters (
track_id INT NOT NULL REFERENCES tracks(id) ON DELETE CASCADE,
level SMALLINT NOT NULL, -- 0 = macro, 1 = fino
cluster_id SMALLINT NOT NULL, -- -1 = NA
method TEXT,
created_at TIMESTAMPTZ DEFAULT now(),
PRIMARY KEY (track_id, level)
);
CREATE TABLE cluster_labels (
level SMALLINT NOT NULL,
cluster_id SMALLINT NOT NULL,
label TEXT,
PRIMARY KEY (level, cluster_id)
);
El diseño multi-level es deliberado: cuando termine music_analysis para los 14,502
tracks, voy a generar un level 2 sobre combined_embedding (audio + descripción
+ letra). Ese clustering debería bajar drásticamente la tasa de noise, porque va a
distinguir entre dos baladas con letras parecidas pero arreglos opuestos.
Para consultar:
-- Todos los tracks del macro "Death & grief"
SELECT t.artist, t.title, cl.label
FROM tracks t
JOIN track_clusters c ON c.track_id = t.id
JOIN cluster_labels cl ON cl.level = c.level AND cl.cluster_id = c.cluster_id
WHERE c.level = 0 AND c.cluster_id = 1;
-- Cruce level 1 ↔ level 0: qué macro recibe a cada cluster fino
SELECT l1.label AS fino, l0.label AS macro, COUNT(*) AS n
FROM track_clusters c1
JOIN track_clusters c0 ON c1.track_id = c0.track_id AND c0.level = 0
JOIN cluster_labels l1 ON l1.level = 1 AND l1.cluster_id = c1.cluster_id
JOIN cluster_labels l0 ON l0.level = 0 AND l0.cluster_id = c0.cluster_id
WHERE c1.level = 1 AND c1.cluster_id >= 0
GROUP BY l1.label, l0.label
ORDER BY n DESC;
Limitaciones honestas
- 44% noise es alto. Mucho de eso son tracks instrumentales con letras escasas, o letras que mezclan varios temas (una canción de protesta política romántica no encaja cleanly en ninguno de los dos clusters). El level 2 con audio va a recoger bastante.
- Labels automáticos genéricos. "Identity / Mental Instability" e "Isolation / Identity" son clusters legítimamente distintos pero los labels no ayudan a diferenciarlos. Una pasada con un LLM mirando los topics+samples por cluster generaría nombres más evocativos.
- Duplicados en la DB. El scanner no deduplica — She Wants Revenge — Wasted Air aparece en 4 carpetas distintas y eso infla algunos clusters. Pendiente para una pasada de limpieza.
- Solo letras, sin audio. Una canción acústica de Deftones y una versión metalcore con la misma letra van a caer en el mismo cluster. Es el costo de no haber esperado a que termine el análisis de audio. Cuando esté, lo rehago.
Próximos pasos
- Terminar
music_analysispara los 13,500+ tracks restantes (ETA ~20 días al ritmo actual con la PSU limitada). - Re-clusterizar level 2 sobre
combined_embedding, que será el promedio normalizado de audio + descripción + letra. - Labels mejores pasando topics+themes+samples de cada cluster a un LLM con un prompt tipo "give me a 2-4 word evocative name".
- Generador de playlists basado en pgvector similarity sobre
combined_embedding, filtrando por BPM/energy/mood del audio analysis.
Pero ya con esto puedo hacer cosas que antes eran imposibles: pedirle a la DB "todas las canciones de mi biblioteca sobre apocalipsis con sentiment negativo" y obtener 67 resultados coherentes en milisegundos.